



La era de la inteligencia artificial (IA) ha traído consigo una revolución en el manejo y procesamiento de datos personales. Mientras que la IA ofrece innumerables beneficios en términos de eficiencia y personalización, también plantea desafíos significativos para la privacidad y la protección de datos personales.
En CANVIA hemos analizado el tema exhaustivamente y recopilamos los puntos más importantes de este debate.
Impacto de la IA en la privacidad de datos
La inteligencia artificial permite el análisis de grandes volúmenes de datos (Big Data), lo que facilita la toma de decisiones más informadas y precisas. Sin embargo, este procesamiento masivo de datos personales puede llevar a la reidentificación de individuos, incluso cuando los datos han sido previamente anonimizados. Esto ocurre porque los algoritmos de IA son capaces de cruzar múltiples fuentes de información, desentrañando patrones que pueden revelar identidades ocultas.
Desafíos y riesgos
Anonimización y reidentificación: Aunque los datos pueden ser anonimizados, la potencia de la IA en el análisis de grandes conjuntos de datos puede revertir este proceso, haciendo posible la reidentificación de individuos. Esto pone en riesgo la privacidad y la seguridad de la información personal.
Sesgo algorítmico: Los algoritmos de IA pueden heredar y amplificar sesgos presentes en los datos de entrenamiento. Este sesgo puede llevar a decisiones injustas o discriminatorias, afectando negativamente a ciertos grupos de personas.
Privacidad diferencial: Para mitigar los riesgos de reidentificación, se han desarrollado técnicas como la privacidad diferencial; que agrega ruido a los datos para proteger la identidad de los individuos sin perder la utilidad del conjunto de datos. Sin embargo, su implementación efectiva sigue siendo un desafío técnico y práctico.
Regulaciones y cumplimiento
La legislación peruana toma como referencia normativa a la Ley Orgánica de Protección de Datos Personales española de 1999, creada en un momento donde el volumen de datos era limitado y se podía tener un mejor control sobre los responsables y sus objetivos. Sin embargo, actualmente el procesamiento de datos es incalculable, dejando a las regulaciones desactualizadas frente a estos nuevos retos.
En este sentido, los escenarios en los que la IA significa un riesgo para los datos personales se concentran en dos aspectos relevantes para la privacidad. El primero es la capacidad de la IA de tomar decisiones automatizadas; y el segundo es la facultad de aprendizaje continuo en base a la experiencia e información proporcionada.
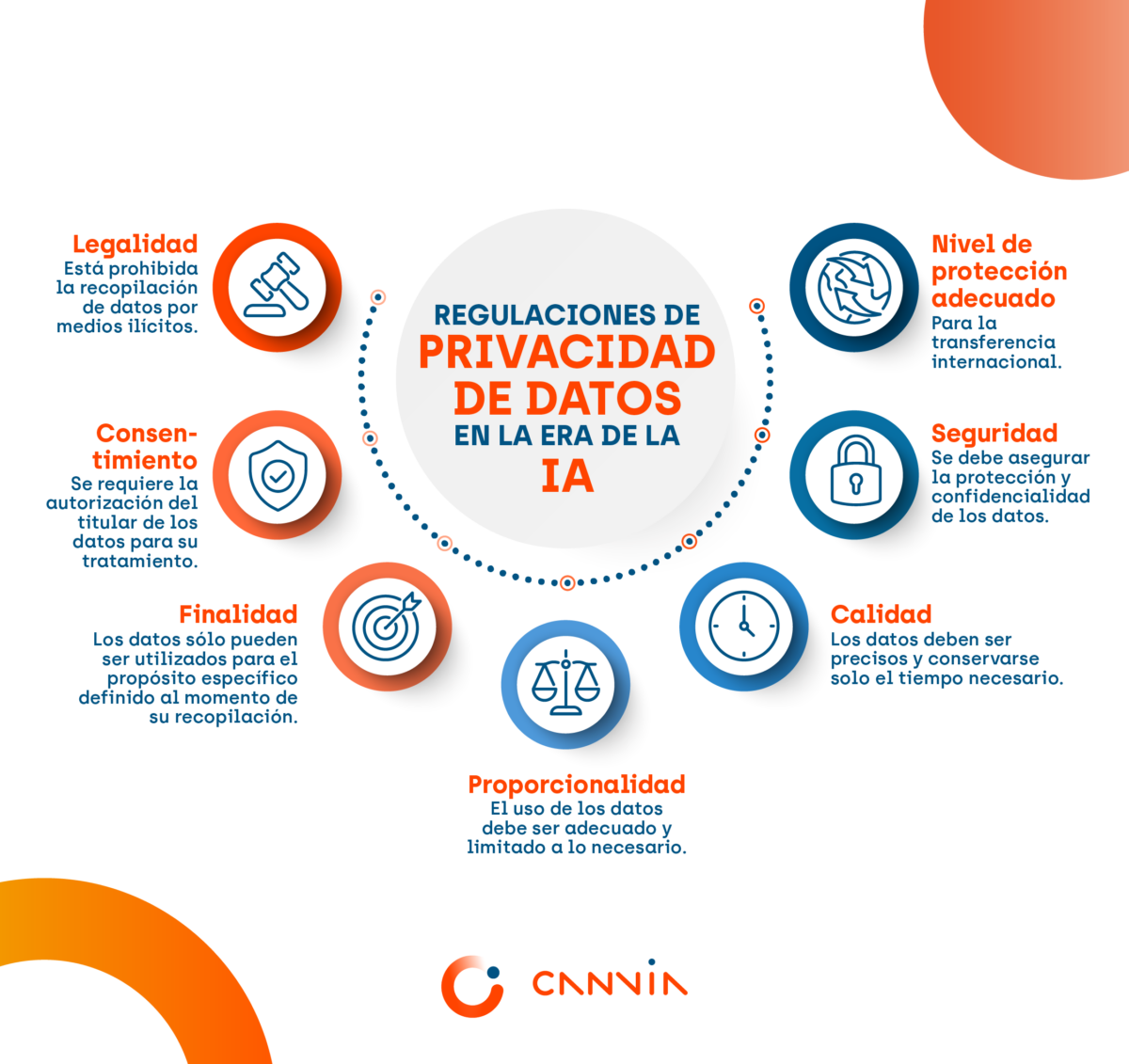
Encontramos lo más cercano a una respuesta en el artículo 28 de la Ley de Protección de Datos Personales, donde se establecen las obligaciones de los responsables del tratamiento de esta información. A continuación, los puntos más relevantes de la referida ley:
Legalidad: El tratamiento de datos debe respetar los derechos fundamentales. Está prohibida la recopilación de datos por medios ilícitos.
Consentimiento: Es necesario obtener la autorización explícita del titular de los datos para su tratamiento.
Finalidad: Los datos sólo pueden ser utilizados para el propósito específico definido al momento de su recopilación.
Proporcionalidad: El uso de los datos debe ser adecuado y limitado a lo necesario para cumplir con su finalidad.
Calidad: Los datos deben ser precisos, veraces y seguros, y conservarse solo el tiempo necesario.
Seguridad: Se deben implementar medidas para asegurar la protección y confidencialidad de los datos.
Nivel de protección adecuado: Para la transferencia internacional, los datos deben recibir un nivel de protección equivalente al previsto por la ley o los estándares internacionales.
Una mirada más ética al Big data y Machine Learning
El uso de Big Data y Machine Learning plantea desafíos para los principios de finalidad y proporcionalidad en el tratamiento de datos personales. Ejemplos como el escándalo de Cambridge Analytica por el cual Facebook recibió una demanda millonaria en 2018 ilustran cómo se pueden violar estos principios al utilizar datos recopilados para un propósito específico con fines diferentes y, a menudo, no revelados.
Cambridge Analytica utilizó datos de millones de usuarios de Facebook para crear perfiles psicométricos y dirigir anuncios políticos personalizados. Esto pone de relieve la importancia del principio de finalidad, que establece que los datos deben utilizarse sólo para los fines para los que fueron recopilados inicialmente. Sin embargo, el Big Data y el Machine Learning a menudo generan resultados inesperados, lo que plantea desafíos para cumplir con este principio.
Además, el principio de proporcionalidad dicta que el tratamiento de datos debe ser adecuado, pertinente y limitado a lo necesario para alcanzar los fines previstos. En el contexto del Big Data, esto significa minimizar la cantidad de datos personales utilizados y asegurarse de que sean relevantes para los propósitos previstos. Sin embargo, esto puede ser difícil de lograr debido a la naturaleza de estas tecnologías, que pueden revelar patrones de datos que conducen a la identificación de individuo; incluso cuando los datos parecen ser anónimos.
El principio de información
El principio de información en la protección de datos personales exige que los ciudadanos sean informados de manera clara y previa sobre cómo se utilizará su información; quiénes serán los destinatarios, la existencia y ubicación de los bancos de datos, entre otros aspectos. Sin embargo, el avance de tecnologías como el Machine Learning plantea desafíos en la explicación del proceso de tratamiento de datos, debido a la naturaleza opaca de algunos modelos de inteligencia artificial, conocida como «Black Box».
A pesar de esta opacidad, el principio de información no exige revelar los detalles internos del funcionamiento de la inteligencia artificial. Más bien, requiere que los titulares de datos comprendan la finalidad del tratamiento; las posibles consecuencias de proporcionar sus datos y sus derechos para impugnar decisiones automatizadas. En este sentido, aunque pueda ser difícil explicar cómo llega a sus conclusiones, la transparencia debe garantizar que los individuos puedan entender y cuestionar las decisiones tomadas por la inteligencia artificial.
Nivel de protección adecuado
Privacidad por diseño: Integrar principios de privacidad desde las etapas iniciales del diseño de sistemas y aplicaciones es crucial. Esto incluye la implementación de prácticas de seguridad robustas y la minimización de la recopilación de datos sensibles.
Gobernanza de datos: Establecer políticas claras de gobernanza de datos que definan cómo se recopilan, almacenan, y utilizan los datos. Esto también implica la capacitación continua del personal en temas de ciberseguridad y protección de datos.
IA Explicable: Desarrollar sistemas de IA que sean transparentes y explicables; permitiendo a los usuarios y reguladores entender cómo se toman las decisiones basadas en datos. Esto ayuda a aumentar la confianza en los sistemas de IA y a detectar posibles sesgos o errores.
La convergencia de la inteligencia artificial y la protección de datos personales presenta un panorama complejo que requiere un equilibrio entre la innovación tecnológica y la preservación de la privacidad. Las empresas y organizaciones deben adoptar un enfoque proactivo para garantizar que los beneficios de la IA no se vean empañados por riesgos innecesarios para la privacidad y la seguridad de los datos.
También te puede interesar: Desmitificando la Caja Negra: La Importancia de la Inteligencia Artificial Explicable (XAI)

