



Un Disaster Recovery Plan (DRP) es un conjunto de procedimientos y directrices que una organización sigue para garantizar la continuidad de sus operaciones tras la ocurrencia de un desastre o incidente que afecte a sus sistemas, datos o infraestructuras. Disponer de un DRP es fundamental para garantizar la resiliencia de una empresa y minimizar los impactos negativos en caso de interrupciones inesperadas.
¿Qué significa Disaster Recovery?
El término «disaster recovery» se refiere a las acciones y procesos que una organización pone en marcha para recuperarse y restaurar sus operaciones normales después de un desastre o incidente que haya causado interrupciones significativas.
El objetivo del disaster recovery es minimizar el tiempo de inactividad y reducir al mínimo los impactos negativos que un desastre pueda tener en las operaciones de una organización. Esto implica tener planes, procesos y recursos en su lugar para recuperar sistemas, datos y servicios críticos de manera eficiente y efectiva.
En el contexto de la tecnología de la información y la gestión de datos, disaster recovery se refiere específicamente a la capacidad de una organización para recuperar sus sistemas y datos después de una pérdida o interrupción. Esto puede incluir la restauración de sistemas de TI, la recuperación de copias de seguridad de datos y la continuidad de las operaciones empresariales.
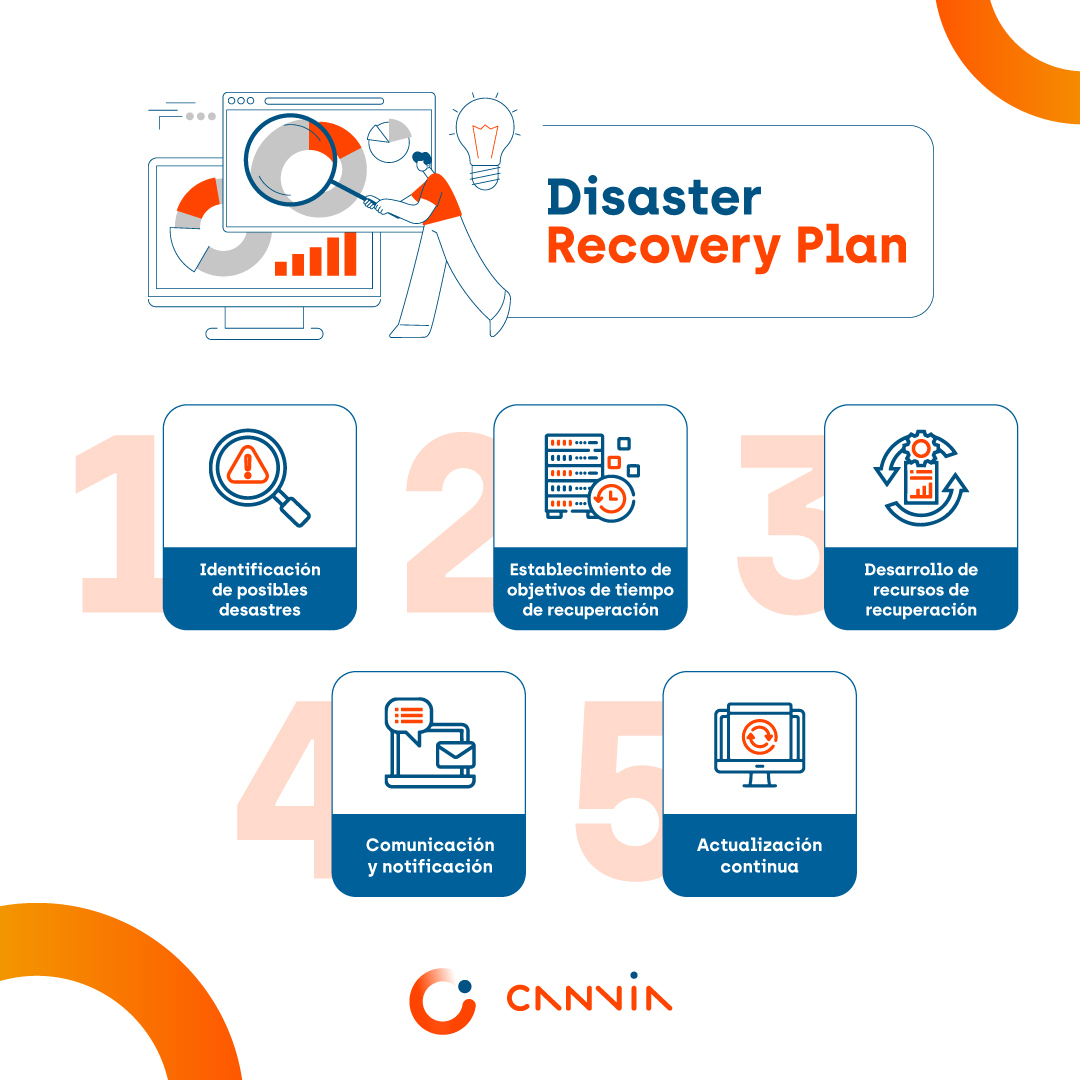
¿Cómo hacer un Disaster Recovery Plan?
Estos son los pasos para crear un Disaster Recovery Plan eficaz:
Evaluación de riesgos e impactos
Empiece por identificar y evaluar los riesgos y amenazas a los que puede enfrentarse su organización. Puede tratarse de catástrofes naturales, cortes de electricidad o ciberataques, entre otros. Considere el impacto que cada uno de estos acontecimientos podría tener en las operaciones de la empresa.
Definición de objetivos
determine claramente cuáles son los objetivos de su PRM (Plan de Recuperación de Medios). Esto puede incluir objetivos específicos de tiempo de recuperación (RTO) y objetivos de punto de recuperación (RPO). El RTO es el tiempo máximo que la organización puede tolerar para la recuperación, mientras que el RPO es la cantidad máxima de datos que la organización puede perder.
Identifique los recursos críticos
Evalúa los sistemas, aplicaciones, datos y recursos que son críticos para las operaciones de su organización. Esto ayuda a priorizar lo que hay que recuperar primero en caso de catástrofe.
Equipo de respuesta ante catástrofes
Designe y forme un equipo de respuesta ante catástrofes. Este equipo debe estar formado por miembros de distintos departamentos de la empresa y debe encargarse de aplicar el PRC (Plan de Recuperación Crítica) en caso de catástrofe.
Desarrolle planes de acción
elabore planes de acción detallados para hacer frente a las distintas situaciones de catástrofe. Deben incluir procedimientos para recuperar sistemas, restaurar datos, comunicarse con empleados y clientes, y otros aspectos críticos.
- Copia de seguridad y recuperación de datos: ponga en marcha estrategias de copia de seguridad y recuperación de datos. Esto puede incluir la realización de copias de seguridad periódicas, el almacenamiento de datos fuera de las instalaciones y pruebas de recuperación.
- Recursos de recuperación: Establezca ubicaciones de trabajo alternativas si es necesario. Esto puede incluir ubicaciones físicas o entornos en la nube que permitan a la empresa seguir funcionando durante la recuperación.
- Pruebas periódicas: Realice pruebas periódicas de su DRP para asegurarse de que funciona como se espera. Esto también ayuda a formar a su equipo de respuesta ante catástrofes.
Comunicación y notificación
Disponga de un plan de comunicación claro que incluya cómo notificar a empleados, clientes, proveedores y otras partes interesadas sobre la catástrofe y las acciones en curso para la recuperación.
Actualización continua
mantenga actualizado su plan de gestión de catástrofes. A medida que evolucionan la tecnología y los procesos empresariales, es importante revisar y ajustar el plan para garantizar su eficacia.
Cumplimiento de la normativa
asegúrese de que su DRP cumple todas las normativas y requisitos legales pertinentes para su sector.
Formación continua
además de las pruebas periódicas, ofrezca formación continua a su equipo de respuesta ante catástrofes para asegurarse de que todos están preparados y al día de los procedimientos.
Es importante recordar que un PRM no es un documento estático, sino un proceso continuo de planificación, aplicación, prueba y mejora. Además, la colaboración y la coordinación entre departamentos y equipos son fundamentales para garantizar que el PRM funcione eficazmente en una situación real de catástrofe. Contar con un PRD bien diseñado puede marcar la diferencia entre la recuperación rápida y eficaz de una empresa y la interrupción prolongada de sus operaciones.
¿Qué es Disaster Recovery AWS?
El Disaster Recovery en AWS (Amazon Web Services) se refiere a las estrategias y soluciones que una organización puede implementar para garantizar la continuidad de sus operaciones y la recuperación de datos y sistemas en la nube de AWS después de un desastre o incidente. AWS ofrece una serie de servicios y herramientas que permiten a las empresas diseñar y desplegar planes de recuperación ante desastres efectivos y escalables. Aquí hay algunas de las características clave de Disaster Recovery en AWS:
Regiones y zonas de disponibilidad:
AWS opera en múltiples regiones en todo el mundo, cada una de las cuales consiste en múltiples zonas de disponibilidad. Esto permite a las organizaciones distribuir sus recursos de manera redundante en diferentes ubicaciones geográficas; lo que aumenta la resiliencia ante desastres naturales u otros incidentes locales.
Amazon S3 y Amazon EBS (Elastic Block Store)
Estos servicios de almacenamiento en la nube de AWS ofrecen opciones de replicación de datos dentro de una región o entre regiones para garantizar la durabilidad y la disponibilidad de los datos. Esto es fundamental para la recuperación de datos en caso de pérdida.
Amazon EC2 (Elastic Compute Cloud)
Las instancias de EC2 se pueden replicar fácilmente en múltiples zonas de disponibilidad o regiones para garantizar la alta disponibilidad y la capacidad de recuperación ante desastres de las cargas de trabajo de la nube.
AWS Backup
Este servicio proporciona una forma centralizada de gestionar y automatizar copias de seguridad de los recursos de AWS, lo que facilita la recuperación de datos en caso de pérdida o eliminación accidental.
AWS CloudFormation
Permite la creación y gestión de pilas de recursos de AWS como código. Esto es útil para reproducir la infraestructura de la aplicación en caso de desastre o para automatizar la creación de recursos de recuperación.
Direct Connect y VPN
Estos servicios permiten establecer conexiones de red seguras entre su entorno local y la infraestructura de AWS; lo que facilita la replicación de datos y la continuidad de las operaciones en la nube.
AWS Lambda
Puede utilizar funciones Lambda para automatizar tareas de recuperación ante desastres, como la activación de recursos de recuperación; la notificación de incidentes o la ejecución de scripts de recuperación.
Site Recovery (ASR)
ASR es un servicio de AWS que ayuda a las organizaciones a orquestar y automatizar la recuperación ante desastres en la nube. Ofrece la capacidad de replicar máquinas virtuales desde un entorno local o de otro proveedor de nube hacia AWS y automatizar la conmutación por error en caso de desastre.
En CANVIA contamos con amplia experiencia en el desarrollo de Disaster Recovery Plan. Si requieres orientación de nuestros expertos, contáctanos.

