



En el vertiginoso mundo de la tecnología, la computación sin servidor ha emergido como una revolución en la forma en que desarrollamos y ejecutamos aplicaciones en la nube. En este blog, desglosaremos qué es exactamente la computación sin servidor, cómo se compara con otras tecnologías como PaaS, y exploraremos sus pros y contras, así como sus casos de uso y cuándo podría no ser la elección ideal.
¿Qué es la Computación Sin Servidor?
La computación sin servidor es un modelo de desarrollo y ejecución de aplicaciones en la nube que libera a los desarrolladores de la carga de gestionar servidores. En este paradigma, los desarrolladores pueden concentrarse únicamente en escribir el código de aplicación, dejando que el proveedor de la nube maneje la infraestructura subyacente. Es esencial entender que, aunque se llama «sin servidor», no significa que no haya servidores en juego, simplemente están ocultos para los desarrolladores.
La esencia de la computación sin servidor radica en la ejecución de código a pedido, escalando automáticamente según la demanda y, crucialmente, cobrando solo por el tiempo de ejecución y los recursos utilizados.
Sin Servidor vs. PaaS, Contenedores y Máquinas Virtuales
Para comprender mejor la magnitud de la computación sin servidor, comparemos sus características clave con otras tecnologías como PaaS, contenedores y máquinas virtuales:
Tiempo de Suministro: En la computación sin servidor, se mide en milisegundos, a diferencia de minutos u horas en otros modelos.
Carga Administrativa: Sin servidor no impone carga administrativa, al contrario de PaaS, contenedores y máquinas virtuales que tienen diferentes niveles de carga continua.
Mantenimiento: Sin servidor y PaaS son gestionados en su totalidad por el proveedor, mientras que contenedores y máquinas virtuales requieren un mantenimiento significativo.
Escalamiento: La escalabilidad automática, incluido el escalamiento a cero, es inherente a la tecnología sin servidor, ofreciendo una respuesta instantánea.
Planificación de Capacidad: Sin servidor no requiere planificación de capacidad, a diferencia de otros modelos que combinan escalamiento automático y planificación.
Sin Estado: La naturaleza sin estado es inherente a sin servidor, garantizando que la escalabilidad nunca sea un problema.
Alta Disponibilidad (HA) y Recuperación de Desastres (DR): Ambos son inherentes al modelo sin servidor sin esfuerzo ni costo adicional.
Utilización de Recursos: La eficiencia del modelo sin servidor es del 100%, ya que no hay capacidad inactiva.
Granularidad de Facturación y Ahorro: Sin servidor se mide en unidades de 100 milisegundos, mientras que otros modelos se miden en horas o minutos.
Sin Servidor, Kubernetes y Knative
Kubernetes, una plataforma de orquestación de contenedores, se integra con la computación sin servidor mediante Knative. Este último proporciona una infraestructura sin servidor para Kubernetes, lo que permite que cualquier contenedor se ejecute como una carga de trabajo sin servidor. La simplicidad de esta integración permite a los desarrolladores centrarse en la creación de contenedores y dejar que Knative se encargue del resto.
Cuándo NO usar la Computación Sin Servidor
Entender las limitaciones de la computación sin servidor es esencial para tomar decisiones informadas. Aquí es donde surge la pregunta crucial: ¿cuándo NO usar la computación sin servidor?
Cargas de trabajo de larga duración: Para tareas que requieren ejecución continua durante períodos prolongados, la computación sin servidor puede no ser eficiente. En estos casos, otros modelos de infraestructura como servicio (IaaS) o incluso servidores dedicados podrían ser más apropiados.
Aplicaciones altamente sensibles a la latencia: En escenarios donde la latencia extrema es crítica, como aplicaciones en tiempo real que requieren respuestas instantáneas, la naturaleza de ejecución a pedido de la computación sin servidor podría no ser la mejor opción.
Cargas de trabajo con requisitos de recursos constantes: Si una aplicación tiene requisitos constantes de recursos y no experimenta fluctuaciones significativas en la demanda, la computación sin servidor podría no ser la opción más rentable, ya que se basa en la escalabilidad automática.
Tareas altamente complejas y continuas: Para tareas que involucran procesamientos complejos y continuos, como simulaciones a largo plazo o procesamiento masivo de datos, otros modelos que permitan la gestión de recursos de manera más específica podrían ser más adecuados.
Pros y contras del enfoque Sin Servidor
Pros
Mejora de la productividad del desarrollador: La tecnología sin servidor permite que los equipos se enfoquen en escribir código, no en gestionar la infraestructura.
Pago solo por ejecución: El modelo de facturación de sin servidor comienza y termina con la ejecución, eliminando costos por capacidad inactiva.
Desarrollo en cualquier lenguaje: Sin servidor es políglota, permitiendo a los desarrolladores codificar en cualquier lenguaje con el que se sientan cómodos.
Ciclos optimizados de desarrollo/DevOps: Simplifica el proceso de implementación y DevOps al eliminar la necesidad de definir infraestructura.
Rendimiento rentable: Para ciertas cargas de trabajo, la computación sin servidor puede ser más rápida y rentable que otras formas de computación.
Contras
Complejidad en cargas de trabajo específicas: Para cargas de trabajo complejas y de larga duración, la computación sin servidor puede no ser la opción más eficiente.
Problemas de latencia: En aplicaciones sensibles a la latencia extrema, el modelo sin servidor podría no ser la mejor elección.
Casos de uso de la tecnología Sin Servidor
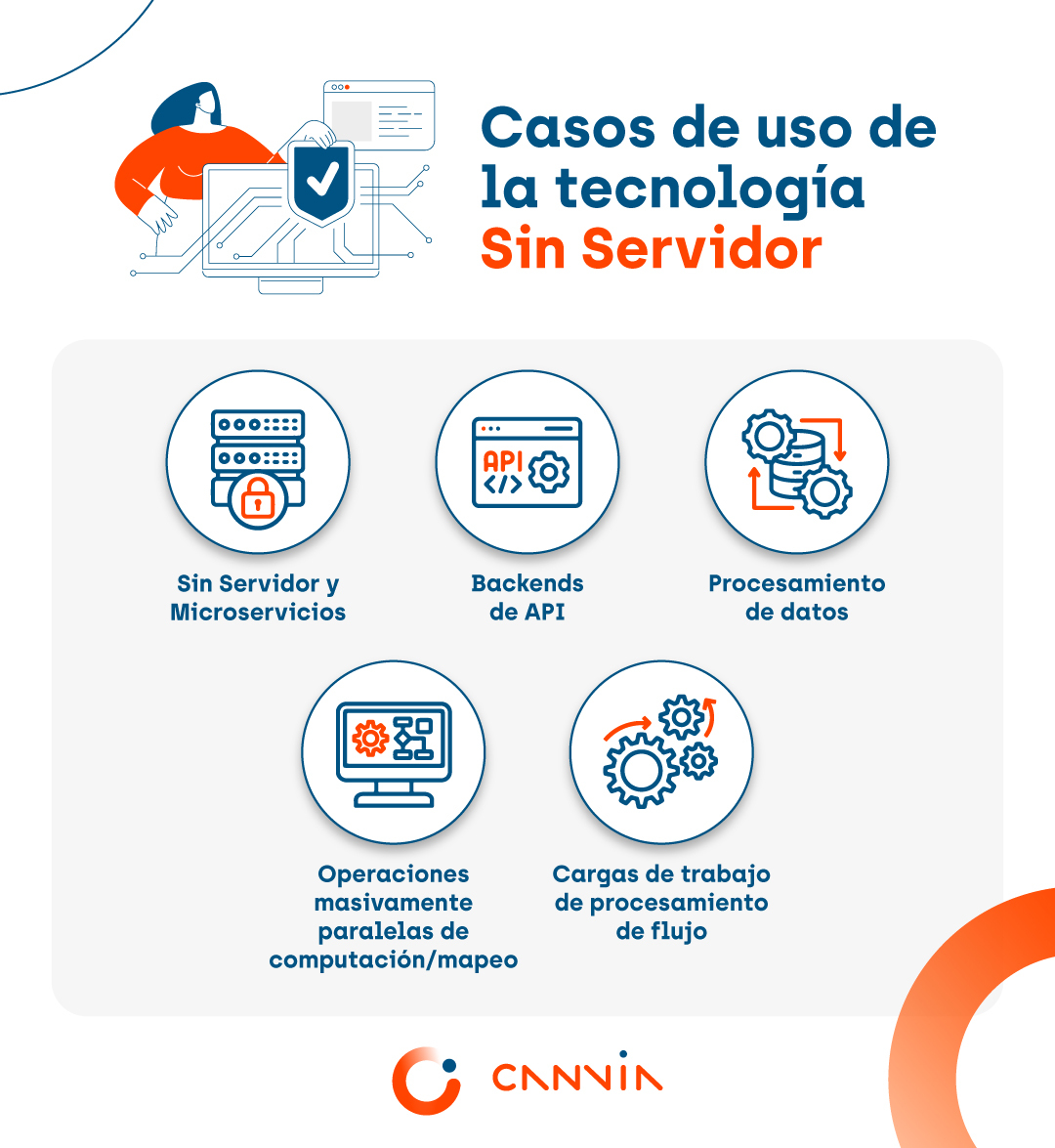
La versatilidad de la arquitectura sin servidor la hace ideal para diversas aplicaciones, tales como:
Sin Servidor y Microservicios: Perfecto para implementar arquitecturas de microservicios, ofreciendo pequeños fragmentos de código, escalabilidad inherente y un modelo de precios eficiente.
Backends de API: Cualquier acción en una plataforma sin servidor puede convertirse en un punto final HTTP, facilitando la creación de APIs.
Procesamiento de datos: Ideal para tareas como enriquecimiento, transformación, validación y limpieza de datos, así como procesamiento de PDF, reconocimiento óptico de caracteres y más.
Operaciones masivamente paralelas de computación/mapeo: Perfecto para tareas paralelizables como búsqueda y procesamiento de datos, web scraping y simulaciones de Monte Carlo.
Cargas de trabajo de procesamiento de flujo: La combinación de Apache Kafka y FaaS permite crear líneas de trabajo de datos en tiempo real.
¡Descubre las maravillas de la computación Sin Servidor con CANVIA!
La computación sin servidor es un viaje emocionante hacia la eficiencia y la innovación en el desarrollo de aplicaciones en la nube. ¿Listo para dar el siguiente paso? Explora las soluciones de CANVIA, líderes en tecnología, y desata todo el potencial de la arquitectura sin servidor.
También te puede interesar: ¿Cómo aplicar la inteligencia artificial en la gestión de mi empresa?

